近日,拓尔思信息技术股份有限公司应用海贝搜索数据库等产品承建的中国知识产权出版社实践案例,入选“2023爱分析·信创产品及服务创新奖”,此案例作为信创数据库的典型案例被收录于《2022-2023爱分析·信创实践报告》(以下简称“《实践报告》”)中。
本次评选活动面向党政、金融、石油等各领域的相关企业及机构,围绕信创实践案例、信创付费客户数量、信创产品收入三个维度对候选厂商进行评估考察。经过多轮专业评审,爱分析最终评选出41个具有参考价值的创新案例予以表彰,并将调研成果与创新案例汇成《实践报告》,为信创数据库、信创云、信创智能运维平台及信创企业数字核心系统等细分市场厂商选型提供参考。
借力信创搜索型数据库,中国知识产权出版社实现数据处理能力全面升级
中国知识产权出版社成立于1980年,是由国务院出资建立的中央文化单位。成立至今,知识产权出版社以打造知识产权全产业链和现代化的出版方式为目标,积极探索云计算、人工智能、大数据等先进技术领域,致力于通过科技赋能传统业务模式。经过多年的科技创新实践,目前已成为我国数字化转型最为成功的国有出版社之一。
(一)内外因素驱动,专利数据搜索系统急需替换
信息化时代以来,为了给予用户更好的专利信息数据查询体验,知识产权出版社借鉴欧洲知识产权出版社模式和技术,搭建了较为基础的数据搜索引擎系统。该搜索引擎系统虽在当时可以满足用户数据查询需求,但随着专利数据量的急剧上升,以及国际局势不断变化,该系统在运维效率、搜索效率、高并发数据处理能力等方面弊端逐渐显露。具体而言,问题主要体现在以下几方面:
1、专业数据检索效率和准确性较低
专利数据搜索表达式多由长句组成,其搜索关键词常有几页之多。在传统数据搜索引擎系统下,由于缺乏完善的长表达式和段句位检索能力,整体数据检索效率较低,并且无法对同段、同句出现的关键词进行精准定位,进而导致整体检索的精确性也难以保障。
2、多语言数据存储和处理能力待提升
作为国内权威的专利查询机构,知识产权出版社存储了来自于世界各地及国内各地区少数民族的多语言专利数据。但在传统数据搜索体系下,不同语言的数据往往被分在不同的数据库中存储和单独处理,整体数据处理效率较为低下。同时,随着语种数量不断增加,数据库数量也显著增加,对出版社的系统运维造成了巨大压力。
3、底层资源竞争现象严重
知识产权出版社专利数据搜索系统不仅能为人工提供数据检索服务,还能支持机器自动化检索及数据处理工作。但在数据高并发情况下,该数据搜索系统由于采用集中式架构,在人工和机器同时使用时,常会出现底层资源竞争现象,不仅导致双方检索效率都大幅降低,还易造成系统宕机的情况发生。
4、受技术“卡脖子”风险较高
随着专利数据量的大幅上升,知识产权出版社原有搜索引擎系统由于技术架构较为老旧,难以应对高并发的数据量,导致问题频发。国内专利领域检索系统普遍采用开源ElasticSearch或者欧洲专利局的技术,运维服务也是国外厂商提供,在国际局势紧张的阶段,系统使用受限严重,且易出现系统运维要求迟迟无法响应的情况发生,整体使用和服务体验较差。
(二)能力整体提升,拓尔思海贝搜索数据库助力专利数据搜索系统重塑
基于上述原有数据搜索系统存在的诸多问题,为了给用户提供更好的使用体验,知识产权出版社决定搭建“中国知识产权大数据与智慧服务系统(DI Inspiro TM)”,以实现对全球103个国家和地区的上百个国外专利网站60亿份专利资源的收录,及中、英、日之间多语言无差别、无障碍的智能扩展检索和及时统计分析,使用户能够轻松获取全球专利信息,完成短时间内的精确检索。
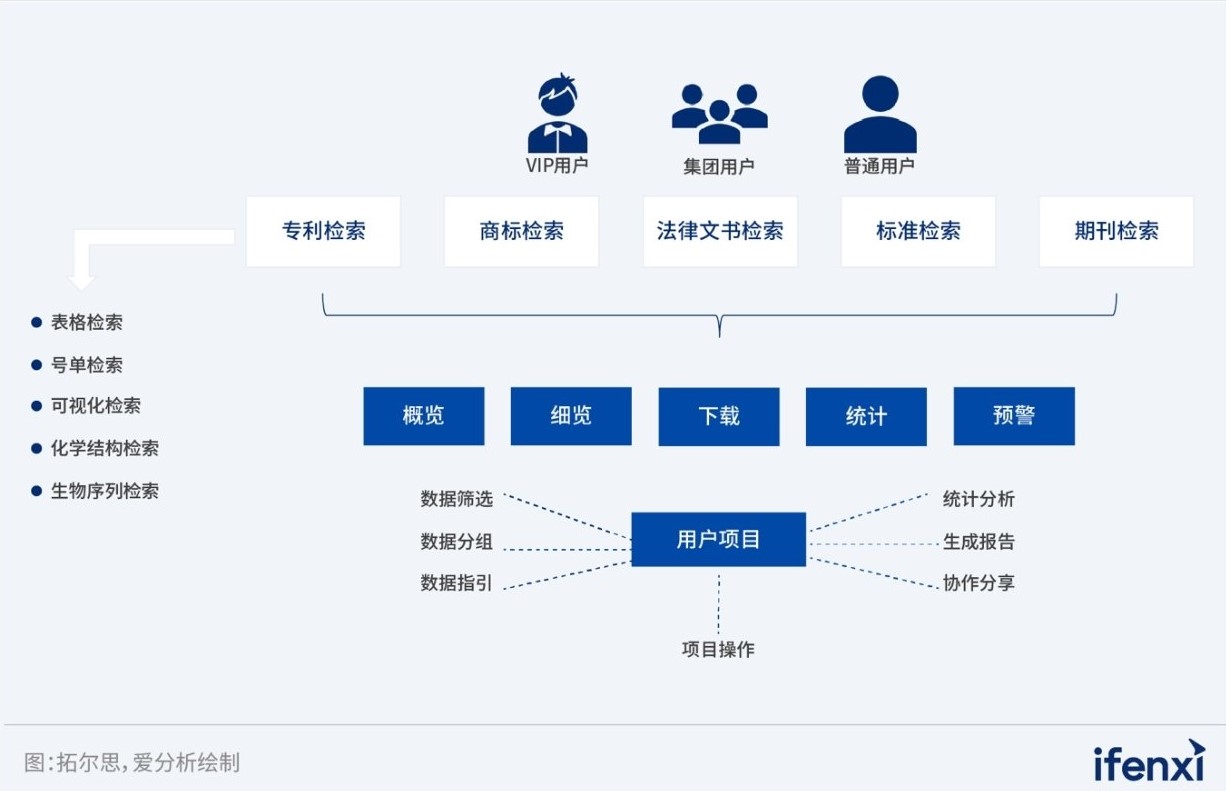
DI InspiroTM系统功能概况
在产品选型阶段,考虑到本系统需要针对全球专利数据进行加工处理,因此知识产权出版社重点考察了搜索型数据库的多语种支持能力,以及专业检索能力。经过多方比对、调研及POC测试,拓尔思海贝搜索数据库凭借着特有的镜像视图、TRS分词器、段句位检索、长表达式检索、倒排索引等核心技术优势,在可扩展性、可靠性、易用性和安全性等多方面表现均优于ElasticSearch等国外开源数据库。最终拓尔思成为了知识产权出版社搭建Dl lnspiroTM系统项目中,最为关键的搜索型数据库的提供商。
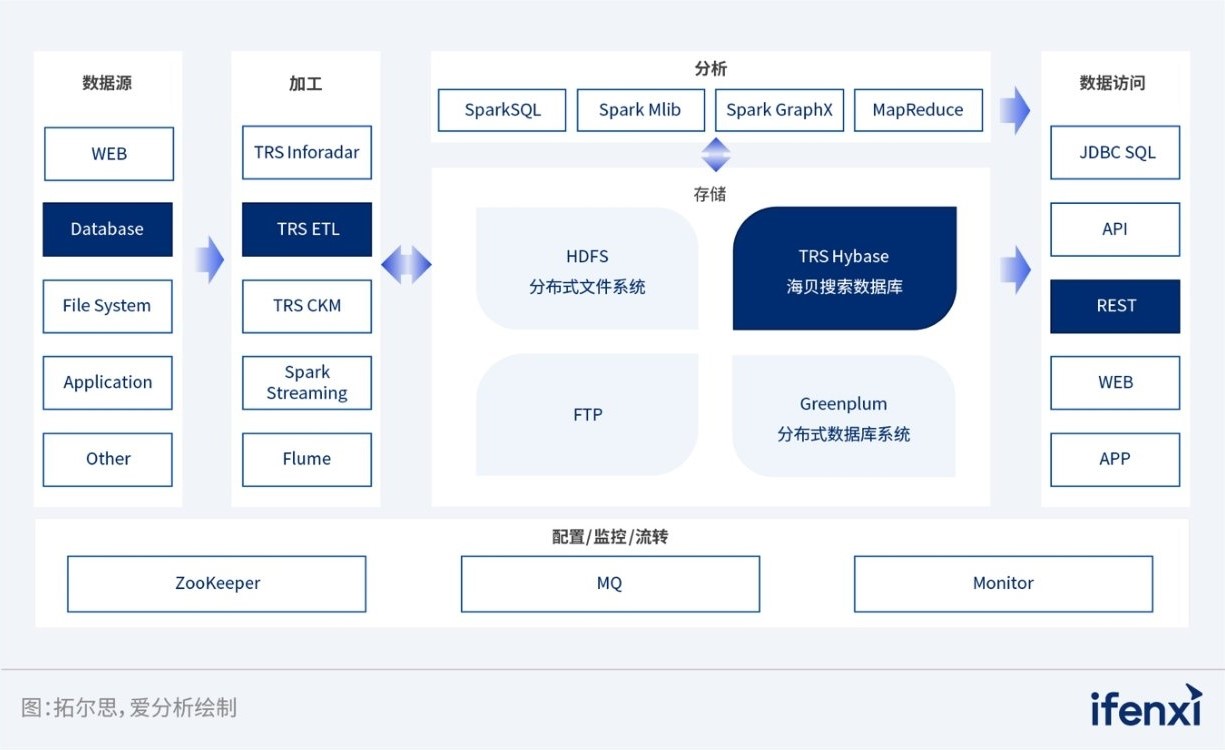
海贝搜索数据库生态流程图
针对现阶段知识产权出版社专利数据搜索系统的痛点及需求,拓尔思输出了以海贝搜索数据库为核心的完整解决方案,在运维效率、数据检索效率及准确性、多语言数据存储及处理能力以及高并发数据应对能力等方面进行全方位补足,具体解决方案如下。
1、完善的索引机制,显著提升数据检索效率及准确性
拓尔思海贝搜索数据库具备包括实时索引、离线索引以及拓尔思特有的倒排索引等在内的完善数据索引机制,能够使该专利搜索系统实现专业的段句位检索以及长表达式检索等多种能力。海贝搜索数据库的全面应用,能够帮助用户在进行长达几页的专利数据搜索时,对同段、同句出现的关键词进行精准定位,大幅提高系统检索的准确率和效率。
2、特有的TRS分词器技术,满足多语言数据处理需求
一方面,拓尔思海贝搜索数据库所具备的多语种数据进行统一存储能力,使该数据搜索系统仅需要部署一个数据库,就能够实现对不同语种专利数据的全量存储,极大简化了整体系统的开发和运维工作;另一方面,海贝搜索数据库特有的TRS分词器技术,使得知识产权出版社专利数据搜索系统使用单一分词器,即可处理包括中日韩等方块文字、英法德等拉丁语系、以及藏文、蒙文、维文等少数民族语言等在内的多语种数据,高效满足多语种数据处理需求。
3、先进的镜像视图能力,有效避免底层资源竞争问题
基于海贝搜索数据库特有的镜像视图技术,知识产权出版社专利数据搜索系统具备了完善的数据读写分离和访问隔离能力。海贝搜索数据库使得该专利搜索系统能够通过镜像技术将数据索引、检索、自动统计分析等功能所需底层资源进行个性化配置和单独隔离,有效避免了数据同时入库+检索,以及人工和机器同时使用数据检索功能等场景下底层资源竞争问题。
4、国产信创,摆脱技术“卡脖子”风险
拓尔思海贝搜索数据库,是国内少有的从底层分词算法到上层全文搜索引擎全栈自研的搜索型数据库。目前海贝搜索数据库已经完成对主流国产化平台移植工作,包括海光、鲲鹏、飞腾、龙芯等芯片,以及统信UOS、中标麒麟、银河麒麟、中科方德等国产操作系统的适配工作。
海贝搜索数据库的全面应用,使得知识产权出版社彻底摆脱了被外国技术“卡脖子”的风险。海贝搜索数据库具备的多种先进技术和高可用、弹性扩容、高安全性等特点,以及拓尔思为知识产权出版社提供的7x24小时运维服务,有效保障该专利搜索系统的稳定性的同时,极大缓解系统开发运维压力。
此外,在安全性方面,拓尔思海贝搜索数据库还具备IP黑白名单、用户逻辑隔离、数据加密存储等多种数据保护能力,帮助知识产权出版社大幅降低专利数据泄露风险。
(三)海贝搜索数据库全面替换,知识产权出版社收益显著
1、数据处理能力大幅加强
依托于海贝搜索数据库所具备的TRS分词器、镜像视图等核心能力优势,知识产权出版社专利搜索系统海量数据检索和多语种处理能力大幅加强,支持参与检索字段多达260+,能够让用户从数以亿计的全球知识产权数据资源中方便、准确地获取到最有用和最有价值的情报信息,有效防范知识产权风险。
2、用户使用体验全面提升
通过海贝搜索数据库对原有数据搜索引擎的整体替换,知识产权出版社成功搭建了Dl lnspiroTM系统。该系统所具备的包括段句位检索、长表达式检索、表格检索、专家检索、批量检索、可视化检索等多样化检索方式,使得用户检索效率和准确性得到了显著优化,并进一步带动了系统使用体验的全面提升。
现阶段,海贝搜索数据库已在知识产权出版社实现了全面部署和替换,并取得了显著效果。未来,随着信创政策的全面铺开,拓尔思与知识产权出版社的合作还将继续深入。拓尔思在创新领域持续为其赋能的同时,基于全面兼容国产主流基础设施及上层数据分析应用等技术架构特点,帮助知识产权出版社实现IT架构全面自主可控。
关注拓尔思官方微信号
后台回复“信创实践报告”
可获取报告原文